Find and replace with type information

Eventually the realization will hit that you’re just trying to approximate what a compiler usually does, but with a regex pattern […] and all you really wanted was type information.
One of the earliest code changes I made with comby removed redundant code in
the Go compiler. After proposing changes, I soon came to the sad realization
that some of them turned out to be just plain wrong.1 What I missed is that a
value’s type could affect whether the code was really redundant or not.
The mechanical, syntactic change removes a redundant nil check and goes like this:
Before
if x != nil {
for ... := range x {
...
}
}
After
for ... := range x {
...
}
The tricky bit is that this change is only valid if x is a slice or map, and
not if x is a pointer or channel.2 If we only have the syntax to go on, there
really is no way to know if the change is valid. Ever since then I’ve
wanted a way to pull type information into comby.
There’s now an experimental way to query type information with
comby that solves this kind of issue. The main idea is to write a rule that pattern matches against
type information in hover tool tips (i.e., type-on-hover data).
where match :[x].lsif.hover {
| ... map... -> true
| ... []... -> true
| _ -> false
}
This kind of rule gives enough flexibility to avoid false positives, filtering
and changing only code where type-on-hover suggests we have a slice (like
[]string syntax in Go) or map (like map[string]string) on our hands.
A few things need to fall in place for this to work, and only a couple of open source projects and languages are supported right now. It’s meant to be an early interface, implemented to generically support future language and project expansions. Read on to learn what’s possible at the frontier of simpler find and replace with types.
Extending comby with type information
When I think about adding type information to comby I want to keep things
simple and easy. Anything too heavyweight isn’t a good fit, because
language-specific tools exist for automating complex changes to the nth degree
(clang for C) and I don’t have time to integrate or maintain such toolchains directly
in comby. To that end, I really just want comby to use an external service
that answers: What is the type of the value at this location in the file?
Type-information-as-a-service is ideal because then I can keep the convenience of matching syntax easily, and outsource accessing language-specific semantic properties as needed. The concept is to expose a property on any matched variable that corresponds to type information (if available). It might look something like this:
func parse(:[args]) where :[args].type == string
For practical reasons, :[args].type would just be a simple string in comby.
In other words, it’s just a string representation of a type (like what you’d
see in a hover tooltip). So, calling this a “type” property is a bit too
simplistic because in reality types are expressions. It isn’t practical to
represent types as such in comby today, which is why I’ve chosen to use a
different name .lsif.hover instead (more on this later).
Incorporating more of the type system to accurately represent terms is welcome
information, and perhaps one day comby will expose a more precise .type
notion. For now we can still make progress on the
find-and-replace-with-types problem in the leading example and many others.
You can skip ahead to what this ends up looking like in comby today but it might make more sense if I tell
you where I’m pulling the type information from first.
Where can I find type information as a service?
I know of only two high-level solutions resembling a service that conveniently provides type information today, and which aim to eventually support all languages. The first is language server implementations of LSP (Language Server Protocol). Language servers expose all kinds of information, and typically include type information in hover tooltips found in editors. With LSP there is no authoritative, centralized language server that you can just query. Instead, language servers are configured for specific projects and either run locally on your machine or get managed by an organization.
The second is a central, public-facing service maintained on Sourcegraph.com that exposes hover information similar to the LSP format (disclaimer: I work at Sourcegraph, but my day job is unrelated to this service). The key difference is that Sourcegraph automatically processes popular repositories on GitHub (currently about 45K) with support for TypeScript, Go, Java, Scala, and Kotlin. It’s also possible to process your own projects (locally, in CI, or GH actions) and upload the data. Once that happens, you can efficently browse or query type information for variables on hover.
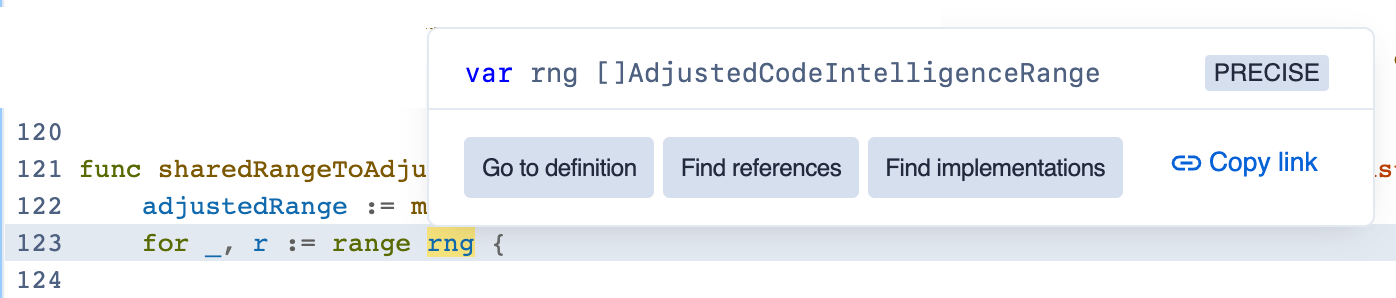
This is exactly the kind of information I need to tell whether a matched variable is a slice, map, channel, or pointer. For supported projects, you just fire a GQL request to get the hover content.
I went with this second option for two reasons.
Managing language servers is too difficult.
Some years ago I had a
prototype where comby starts up language servers and queries them. It was a
pain to manage and configure servers, especially on various open source
projects. Although I succeeded at getting things up and running for about 5
languages and various projects, I didn’t like how brittle things were
and discontinued the effort. In principle there’s
nothing stopping an ambitious developers to generically integrate comby with
LSP (and even restrict it to one language or project). I just don’t want to
write or maintain that kind of thing.
Network requests to central services are easy. Ultimately I implemented
generic support in comby to pull hover information from any central service
exposing type information over HTTP (less hassle for me), and the default
service with the best support for that right now is Sourcegraph.com.
Using comby with types today
Type information is accessed in code hovers via :[x].lsif.hover
syntax. This syntax resolves hover information at the end position of :[x] when
comby succeeds at retrieving this information from an external service.
Until generic code intelligence services become more definitive, inspecting
hover information is currently the most direct way to access type information
from a central service today.
The lsif part is a reference to LSIF,
a schema related to LSP and SCIP.
Go example redux, this time without disappointment. Adding a rule to check type-on-hover information solves the false positive issues from before.
where match :[x].lsif.hover {
| ... map... -> true
| ... []... -> true
| _ -> false
}
I settled on this rule based on the type-on-hover information I saw for
potential matches in popular Go repositories. Here are some matches and
non-matches I found by using the new :[x].lsif.hover ability.
✅ struct field ExtraHeaders map[string]string — we want to match this, it’s a map!
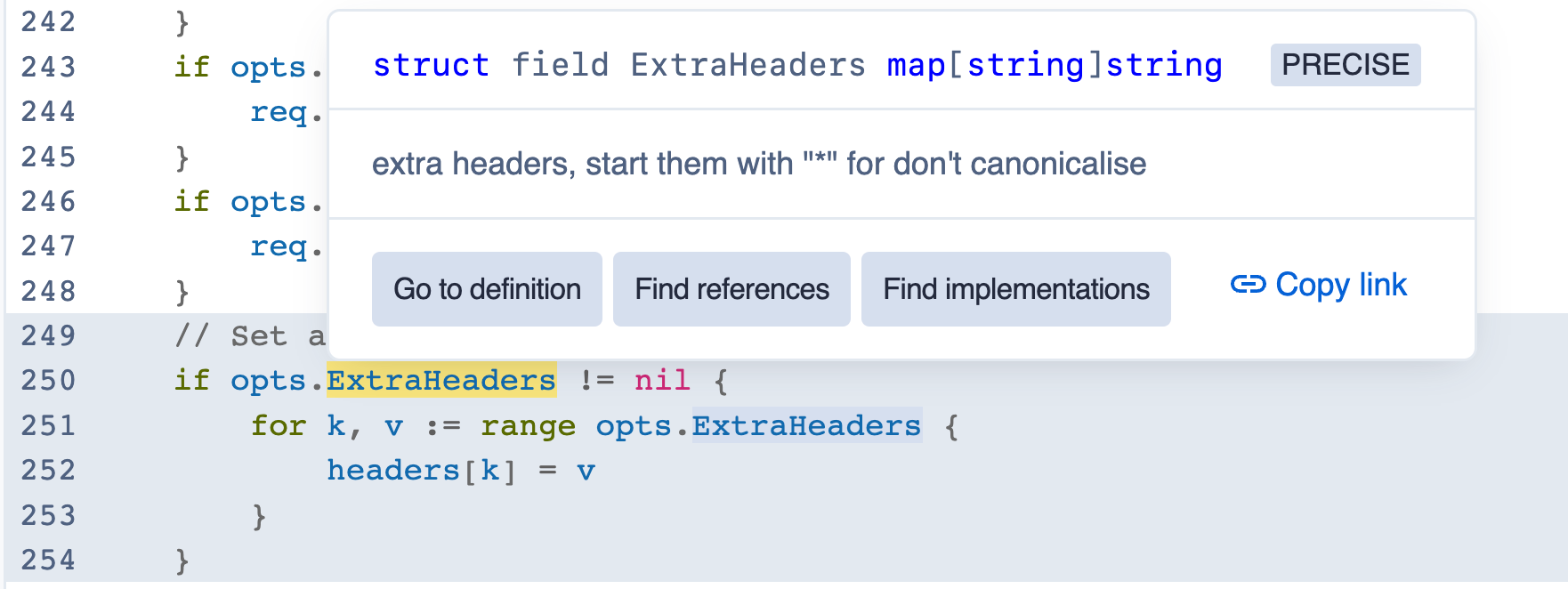
- This is a file in
github.com/rclone/rclone. You can browse it and see the redundantnilcheck for yourself ↗
✅ struct field ImportStateReturn []*InstanceState — we want to match this, it’s a [] slice!
- This is a redundant
nilcheck ingithub.com/hashicorp/terraform
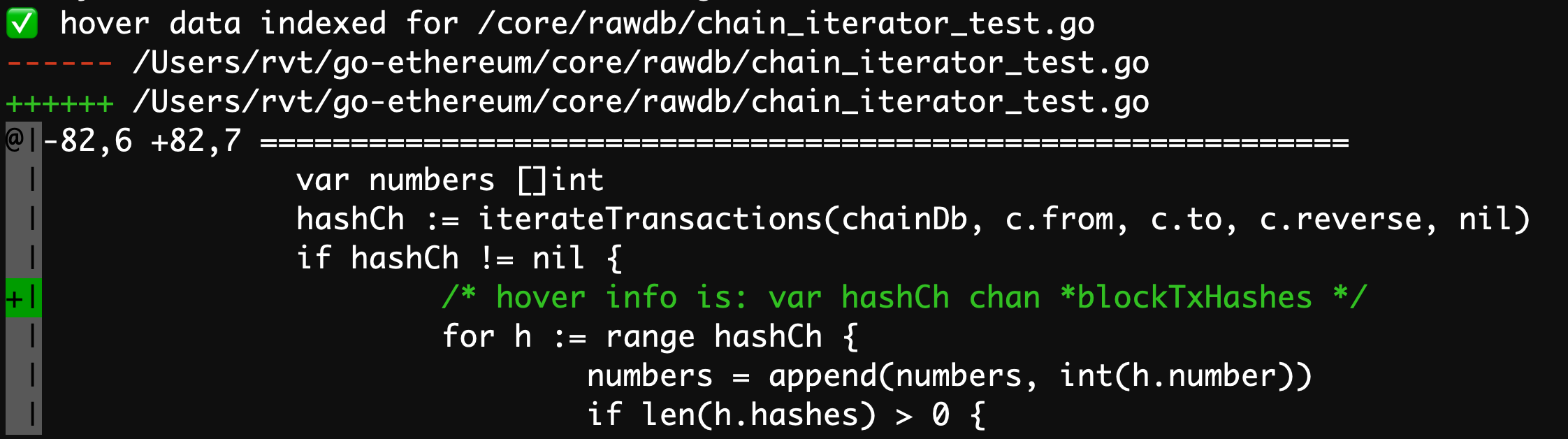
❌ var hashCh chan *blockTxHashes — we don’t want to match this, its a channel type chan!
- This valid
nilcheck lives ingithub/ethereum/go-ethereum
You can use other patterns to achieve similar things, with deeper or looser
precision. For example, you could write a regex pattern to match undesired
cases where the string contains chan, and then explicitly exclude such matches.
| ...:[~\bchan\b]... -> false
Expand to see the full command line invocation I ran on each project
You first need to clone each repository, change to the root directory, and can then run this command if you have a recent version of comby. See footnotes if you want more info for running things yourself.
COMBY_MATCH="$(cat <<"MATCH"
if :[x] != nil {
for :[e] := range :[x] {
:[body]
}
}
MATCH
)"
COMBY_REWRITE="$(cat <<"REWRITE"
for :[e] := range :[x] {
:[body]
}
REWRITE
)"
COMBY_RULE="$(cat <<"RULE"
where match :[x].lsif.hover {
| ... map... -> true
| ... []... -> true
| _ -> false
}
RULE
)"
comby "$COMBY_MATCH" "$COMBY_REWRITE" -rule "$COMBY_RULE" .go
This behavior is admittedly an approximation to
get type information. For example, .lsif.hover may also contain doc strings
and matching may need to work around this extraneous data. But (I assert) it is often good
enough for various type-sensitive changes. You can also use :[x].lsif.hover
in the rewrite output.
This will let you inspect the information exposed
by :[x].lsif.hover. In fact, that’s exactly what I did to decide how to match on type information
for my rule. I just substituted it in a Go comment in the output.
Expand to see sample match and rewrite templates for inspecting hover info
Match
if :[x] != nil {
for :[e] := range :[x] {
:[body]
}
}
Rewrite
if :[x] != nil {
/* hover info is: :[x].lsif.hover */
for :[e] := range :[x] {
:[body]
}
}
Which projects and languages does this work for?
If a repository is processed with precise type-on-hover on Sourcegraph.com, accessing that information via
comby should just work. This means you can use tools to process and upload
this information with your own
TypeScript, Java, Scala,
Kotlin, or
Go projects to Sourcegraph and
comby will be able to access hover information for them.
These tools encode type
information and other data using
SCIP,
which is related to the Language Server Index Format
(LSIF/LSP)
but with efficiency in mind.
If you happen to work at a company with a running Sourcegraph instance that
indexes any of these languages, you’re in luck: setting
LSIF_SERVER=https://your-instance/.api/graphql when you run comby will enable it to get
hover information from your instance.3
See more at the end of the post if you want to try things out yourself.4
When is type information actually useful for find and replace?
I’ve gotten this question a couple of times from my developer friends, and often they’re able to nod their heads that accessing this kind of type information is theoretically useful, but they really want to see concrete examples. The reality is that vast amounts of changes that simplify expressions, modernize functions, or apply lint-like fixes require type information.
The connection might not be obvious because accessing type information is typically buried deeper in a linter or compiler, after the initial layer of syntax concerns (parsing), and tightly coupled to the language. So to give a sense, here are some diverse ways where explicitly pulling in type information supercharges code search and refactoring.
- › We’ve covered a Go example, which is a code simplification implemented in
staticcheck. Here are many more code simplifications with the same flavor—the last time I counted, at least 18 of the 35 checks require type information to ensure correctness.
› In Java,
try-catch-finallyblocks can be replaced with more succincttry-with-resourcesblocks that automatically close resources, like files. The catch? We need to know whether an object implements theAutoCloseableinterface. This also is type information we need to correctly refactor.› Equality operators
==on generic values can lead to Bad Things™. This is a well-known pitfall in JavaScript and found in other languages too. See this post on the “perils of polymorphic compare” in OCaml, and type coercion simplifications for Erlang in Section 3.2 of this paper. In statically typed languages like OCaml, you can use equality operators for a specific type likeInt.equalorString.equalinstead. But when you look at an expression likex == y, how do you know if it’s safe to replace the expression with something likeInt.(x == y)orString.(x == y)or something else? That’s right, you need something to tell you the type ofxory.› Types make static analysis more precise and help remove false positives in bug reports. Analyzers like Semgrep and PMD include ways to reference type information for checks like "only report a potential SQL injection if the argument passed is of type string (
intis safe)" or "only report a violation if a loop index type is afloat".› Reducers like
creduceandcomby-reducerautomatically transform a program in valid ways to produce smaller source code that triggers the same runtime behavior of the original. Reducers can use type information to more precisely guarantee valid programs, or use type information to make the program smaller. For example,creducewill remove the&operator in C code depending on the expression and its type (see the complete description here).
In these examples, types can sometimes be inferred by matching on existing syntax definitions, but things will quickly become intractable as you try to follow the type propagation in and across functions. Eventually the realization will hit that you’re basically just trying to approximate what a compiler usually does, but with a regex pattern. Really all you want is for the information to exist, and a convenient way to look it up.
A more general view on integrating type information
I’ve long wanted an interface that effectively decouples accessing general
semantic properties from patterns that match syntax. This stems from the fact
that there’s virtually no mature tools today where you can access deep semantic
properties without needing to write code or interface with heavyweight
tooling like clang (the exception might be IntelliJ structural
search-and-replace). By deep I mean not just locally scoped type information
or primitives. Although the lsif.hover data today is a string representation,
it is a deep, project-global representation of the underlying type. As I’ve
continued developing comby I’ve realized that it just makes sense to
decouple language-general syntax pattern matching and language-specific
semantic properties. It works well to compose syntax pattern matching and
type information for those lightweight code changes or checks in the examples
above.
The leading thought is that semantic properties don’t need to be restricted to
just type information. Precise “rename symbol” operations in editors (say, to
rename a function and update its calls) rely on semantic relations over
definitions and references to work. Similar to exposing type information,
comby could also expose information and operations on “all references for the
syntax matched at this point” or resolve "definitions for this matched syntax".
Because comby is a more general syntactic rewriter than editor
find-and-replace prompts, these semantic properties could unlock easier ways to
do things like instrument code (e.g., add a debug statement after every
reference) or selectively emit information to build domain-specific semantic
language models.
The idea of exposing semantic information alongside syntactic changes is not new. The closest and most cogent discussion on this topic I’ve found uses an apt term: semantic selectors. Unfortunately the paper is paywalled, but here’s an excerpt:
Program manipulation systems provide access to static semantic information through semantic selectors which yield attributes associated with nodes. For example, a manipulation system for a statically scoped language will supply a semantic selector that yields the defining occurrence of a given name (i.e., the point where the name is defined).
Language Design for Program Manipulation by Merks et al., IEEE Transactions on Software Engineering, 1992. ↗
Strikingly, tools today still don’t expose semantic information like this without heaps of complexity and difficulty (think about installing and running language-specific toolchains, or writing analyses using them). The current trend of language-server-like tools is the closest effort to a simpler semantic interface, but it is heavily influenced by code editor workflows. I’m hopeful for an ecosystem with broader semantic selectors as a service that expose deep information for all languages. Find and replace with types is one of the best reasons I’ve found for doing that so far.
Footnotes
1. Original Go PR
2. The underlying semantics for a range operation differs based on the type of
x. When x is a nil slice or map, no check is needed, and the range
operation is effectively a no-op (my guess is this behavior is probably
implemented for convenience). But when x is a pointer or channel, a missing
check could lead to a null dereference or blocking, respectively.
3. Please note nothing in this post is a Sourcegraph-endorsed
or maintained feature, it’s a personally maintained experimental feature in comby added by me, the author.
4. Some quick usage notes if you decide to try the things in this post:
- › You need to use the latest docker distribution or build comby from source. This because the latest version is not yet available to Linux or via brew on macOS.
› You still need to clone the target repository locally (like github.com/rclone/rclone), then run comby at the root of the project.
› I’m not sure which projects are automatically indexed, but comby will
notify you if a lsif.hover property isn’t available.
› For help with Sourcegraph stuff visit their Discord. For comby things visit the gitter channel.
› Using comby to access hover info is experimental and subject to change.